大數(shù)據(jù)學(xué)習(xí)筆記 Day01 大數(shù)據(jù)框架與數(shù)據(jù)挖掘及分析初探
一、大數(shù)據(jù)概述
大數(shù)據(jù)(Big Data)是指無法在一定時間范圍內(nèi)用常規(guī)軟件工具進行捕捉、管理和處理的數(shù)據(jù)集合,具有4V特征:
- Volume(大量):數(shù)據(jù)體量巨大,從TB級別躍升到PB乃至ZB級別。
- Velocity(高速):數(shù)據(jù)生成和處理速度快,要求實時或近實時分析。
- Variety(多樣):數(shù)據(jù)類型繁多,包括結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。
- Value(低價值密度):數(shù)據(jù)價值密度相對較低,需通過挖掘分析提煉高價值信息。
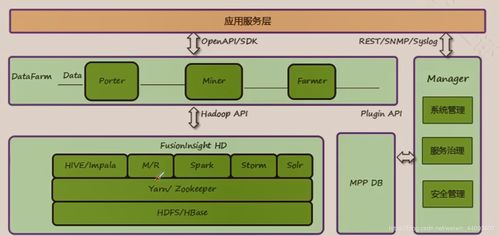
二、主流大數(shù)據(jù)框架
大數(shù)據(jù)框架是處理海量數(shù)據(jù)的軟件庫和工具的集合,旨在解決存儲、計算和分析的難題。
1. Hadoop生態(tài)系統(tǒng)
- HDFS(Hadoop Distributed File System):分布式文件系統(tǒng),提供高吞吐量的數(shù)據(jù)訪問,是Hadoop的存儲基石。
- MapReduce:分布式計算編程模型,將任務(wù)分解為Map(映射)和Reduce(歸約)兩個階段,適合批處理。
- YARN(Yet Another Resource Negotiator):資源管理和作業(yè)調(diào)度框架,允許多個數(shù)據(jù)處理引擎(如Spark)在Hadoop集群上運行。
- Hive:基于Hadoop的數(shù)據(jù)倉庫工具,提供類SQL查詢(HiveQL),將查詢轉(zhuǎn)換為MapReduce任務(wù)。
- HBase:分布式、可擴展的NoSQL數(shù)據(jù)庫,適合實時讀寫大數(shù)據(jù)集。
2. Spark
- 一個快速、通用的集群計算系統(tǒng),相比MapReduce,通過內(nèi)存計算顯著提升迭代和交互式查詢速度。
- 核心抽象是RDD(Resilient Distributed Dataset),提供Spark SQL、Spark Streaming、MLlib(機器學(xué)習(xí)庫)和GraphX(圖計算)等組件。
3. Flink
- 一個流處理和批處理的開源框架,以流處理為核心,將批處理視為有界流。
- 提供高吞吐、低延遲、Exactly-Once語義的流處理能力,適合實時分析場景。
三、數(shù)據(jù)挖掘及分析
數(shù)據(jù)挖掘是從大量數(shù)據(jù)中提取未知的、有價值的模式和知識的過程,是大數(shù)據(jù)分析的核心。
1. 數(shù)據(jù)挖掘主要任務(wù)
- 分類(Classification):預(yù)測離散類別標簽,如判斷郵件是否為垃圾郵件。
- 聚類(Clustering):將數(shù)據(jù)分組為相似對象的集合,如客戶細分。
- 關(guān)聯(lián)規(guī)則學(xué)習(xí)(Association Rule Learning):發(fā)現(xiàn)變量間有趣的關(guān)系,如購物籃分析(啤酒與尿布)。
- 回歸(Regression):預(yù)測連續(xù)數(shù)值,如房價預(yù)測。
- 異常檢測(Anomaly Detection):識別異常數(shù)據(jù)點,如信用卡欺詐檢測。
2. 數(shù)據(jù)分析流程(CRISP-DM)
- 業(yè)務(wù)理解:明確分析目標和需求。
- 數(shù)據(jù)理解:收集、探索和描述數(shù)據(jù)。
- 數(shù)據(jù)準備:清洗、轉(zhuǎn)換和集成數(shù)據(jù),構(gòu)建分析數(shù)據(jù)集。
- 建模:選擇和應(yīng)用數(shù)據(jù)挖掘算法。
- 評估:評估模型是否滿足業(yè)務(wù)目標。
- 部署:將分析結(jié)果應(yīng)用于實際業(yè)務(wù)。
3. 常用工具與技術(shù)
- 編程語言:Python(Pandas, Scikit-learn)、R、Scala。
- 數(shù)據(jù)處理:SQL、Pandas、Spark SQL。
- 機器學(xué)習(xí)庫:Scikit-learn、MLlib(Spark)、TensorFlow/PyTorch(深度學(xué)習(xí))。
- 可視化:Matplotlib、Seaborn、Tableau。
四、與展望
Day01的學(xué)習(xí)聚焦于大數(shù)據(jù)的基礎(chǔ)框架和核心分析概念。理解Hadoop、Spark等框架的定位與特點,是構(gòu)建大數(shù)據(jù)處理能力的基礎(chǔ)。數(shù)據(jù)挖掘作為從數(shù)據(jù)中提取價值的引擎,其任務(wù)和流程為后續(xù)的深入實踐提供了方法論指導(dǎo)。后續(xù)學(xué)習(xí)將深入各框架的實戰(zhàn)應(yīng)用與具體算法的實現(xiàn)。
關(guān)鍵要點回顧:
- 大數(shù)據(jù)4V特征是理解其挑戰(zhàn)的出發(fā)點。
- Hadoop適合大規(guī)模批處理,Spark以內(nèi)存計算見長,F(xiàn)link專精流處理。
- 數(shù)據(jù)挖掘通過分類、聚類等任務(wù)將數(shù)據(jù)轉(zhuǎn)化為洞察。
- 分析流程(如CRISP-DM)確保項目有序、有效地進行。
如若轉(zhuǎn)載,請注明出處:http://m.kigigi.com.cn/product/17.html
更新時間:2026-06-19 16:49:15